Demystifying Tape Reliability
Why does there continue to be so much discussion of tape and tape library reliability in the trade press? The not-so-obvious answer is that the tape library industry has discovered the truth; library systems are more reliable than single drives. Unfortunately, that message is always lost in the confusion of jargon and reliability terms. It is time for a new perspective and a definition of reliability consistent with the requirements of today’s mission critical application serving environment. The simple reality is that failures happen! No pursuit or variant of MTBF terminology will result in a meaningful and useful understanding of how to build mission-critical-capable network applications.As shown in Figure 1, reliability defines many terms that span data reliability, device (drive or system) reliability, and other systems concerns. Yet, the proof of reliability comes with the company’s reputation, warranty, and service policies, not with a phony number and assumptions about utilization, duty cycle, and replacements. We need a new metric and we propose that if you accept that failures happen, then it’s not reliability that is of concern. It is system availability.

Figure 1.
To further illustrate, consider the overused reliability metric Mean Time Between Failure, MTBF. If you used the same methods that the tape library industry uses to calculate MTBF for tape systems and applied it to the human body, you would arrive at 18.2 million hours. The claim that a human body, with replacement, field upgrades, and not counting infant mortalities, has a MTBF of 2,078 years1, obviously has no relationship to life expectation. What conclusions can you draw from a term like this? How do you even select a "reliable body", using these misleading methods?
The lesson becomes clear by looking at the Annual Failure Rate, AFR2, for disk drives. Leaving the definitions aside, let’s look at what AFR tells us. Keep in mind that failures happen! In Figure 2, disk drives are compared to tape drives as well as disk and tape systems. Even with MTBFs of several hundred thousand hours, disk drives fail annually. For disk drives, an AFR of 3.8% is equivalent to saying a single disk drive has a probability of not failing in a given year of 96%.

Figure 2.
High-end tape drives are good, but still not as good as disk. These failure probabilities compound when building an array or a system, utilizing multiple drives. A 50 drive disk array experiences an average of 3 drive failures per year. (In comparison, a 1000 drive array sees disk failures weekly!) Two important lessons leap out of this data. RAID does not stop failures. We all accept RAID as the highest reliability storage architecture available. However, RAID is a system solution designed to provide high availability and high data integrity through fault tolerance, not MTBF or AFR. These are completely different concepts! Failures still occur and high availability system architectures are required to prevent downtime, protect data, and insure continued performance. In the disk world, RAID arrays, not JBOD3, are the solution for reliability. In the tape arena, it is libraries with multiple drives, RAID tape arrays, and multiple libraries with the capability to fail over to available spares that provide equivalent service. The solution is not higher MTBFs.
The second key lesson is based on the experience of the tape library industry and its customers. A well designed library with multiple drives will achieve a lower failure rate than just independent single drives, because the library presents a consistent and controlled environment to the drives. Thus, the real-world AFR for a tape library system is lower than for a combination of single drives. This is very important to understand.
The solution to the dilemma of reliability definition hides in the process used for product selection. In purchasing network equipment, we all go through a very similar selection process. It consists of three eliminators and seven selectors.
| ELIMINATORS | SELECTORS |
|---|---|
| Reliability | Performance |
| Compatibility | Service & Support |
| Price (within a window) | Availability |
| - | Scalability |
| - | Manageabilityy |
| - | Flexibility |
| - | Price (Absolute/Cost of Ownership) |
Product selection begins with an elimination process: If a product is not reliable, then I will not consider it. If it is not compatible with my computing platforms or if the price is out of range, I will not consider it.
The notion of "reliable" is relatively vague at this point and dependent on experience and references. Do you really shop for the best MTBF? Probably not. It is more likely you evaluate and select products based on the list of selectors.
It’s our collective experience that products fail and do not install with ease. That is why "service and support" are always ranked at the top of everyone’s list of product selectors. Below service are the four "abilities", availability, scalability, manageability, and flexibility. Once we’ve boiled these down, absolute price becomes important.
Put in context, service/support and availability define operational reliability as what happens when a failure occurs. As an administrator, do not look for absolute reliability numbers; they are meaningless. Instead, look for relationships with high levels of service, extended warranties, and then build architectures that keep your systems available.
System availability is defined in the network as the probability that a system is available at a given instant. The system availability term expresses the expected percentage of time a system is available as a percent of total possible uptime. Using this method, networks can be rated on their unavailability and categorized into a hierarchy of availability classes. Figure 3 presents the standard definitions for network availability which range from "unmanaged" with 50,000 minutes of downtime per year to "ultra-available" with 0.05 minutes of downtime per year.
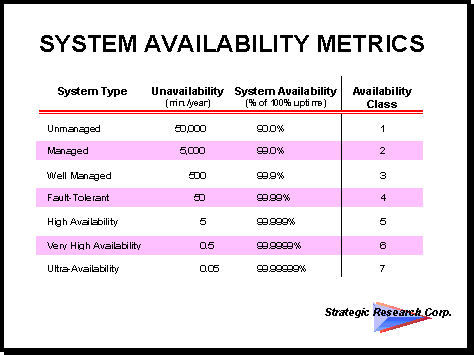
Figure 3.
By applying these same principals to disk and tape products the whole discussion of reliability comes into focus. When all tape products are arranged based on their system availability, a hierarchy is formed that corresponds to network system availability.
In late 1996, the RAID Advisory Board, RAB, published a definition of how to implement various levels of availability for RAID systems. Three classes of availability were identified, fault resistant, fault tolerant, and disaster tolerant.
We are proposing the same definition set for tape using the categories of fault resistant and fault tolerant so that we communicate independent of drive technology. Figure 4 presents the architecture. Each level in the availability hierarchy is related to the system availability class defined in Figure 3.

Figure 4.
Single drive-based systems are failure sensitive and need to be recognized as such, regardless of their "reliability". When (not if) a failure occurs, the entire system is down. In contrast, the first failure resistant categories use multiple drives. If one drive is down, then the process can fail-over to an alternate drive. Operations continue even if at a reduced rate. Multiple-drive systems based on libraries or RAID tape arrays are also failure resistant, but operate at a higher level of availability because of their inherent fail-over capability. The next level in the hierarchy is configurations using multiple drives in multiple libraries and RAID tape arrays built into libraries. Redundancy creates a degree of failure tolerance and we can truly talk about high availability tape systems. This hierarchy takes into account the reliability experience of the library community. Libraries have higher availability than hordes of single drives and multiple libraries have higher availability than all but specialized "high availability" libraries such as IBM’s 3494. Don’t forget that good library management software is also essential.
Use the information presented in this paper to resolve what types of tape systems to purchase from an "operational reliability" perspective. Our recommendation is to begin with understanding your availability needs. First, measure your downtime costs and decide what degree of system downtime you can tolerate. (If you do not know how, use the downtime calculator on the Network Buyer’s Guide at http://www.sresearch.com/java/105308.htm.) Next, determine your uptime requirements by application. Uptime requirements translate to your system availability needs. Use this to determine what class systems you need to install. Figure 5 illustrates the balance point achieved where improved system availability reduces downtime cost without spending too much on equipment. Implement too low a system availability and your downtime costs become excessive.
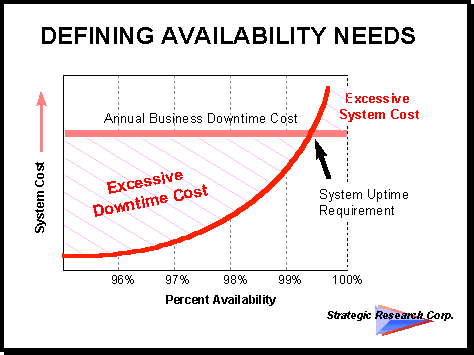
Figure 5.
These same principals apply to tape. Our recommendation is to install a tape system with a system availability corresponding to your downtime requirements. According to the hierarchy presented in Figure 4, tape system availability is scaleable. You can migrate to higher classes through purchase of the right products rather than just throwing more tape drives at the problem. Achieving high availability is more important than "reliability".
By using the "operational reliability" approach, the principals of purchasing the proper tape system include looking for a vendor with a commitment to service and support. This is manifested in the length and quality of the warranty, availability of spares, and onsite support. Purchase a configuration that gives you the system availability you need and can be scaled for future expansion. Definitely consider libraries which are superior and have many benefits, including a much lower cost of operations when compared to individual drives. In addition, select robust library management software to operate the library and provide fail-over functionality.
This paper began with the rhetorical question, "What is tape reliability?" In a mission-critical application, the basic premise is that the backup system can not cause a failure, downtime, a system hang, place data at risk, or impact system performance. Traditional reliability thinking does not address the total system availability concern. It takes a superset of approaches and a relationship with a vendor to successfully implement a high availability architecture and achieve what we have called "operational reliability".
- Source: Reliability Revealed, John Gniewek & Paul Seger, IBM, 3/95
- AFR is calculated as (100% of the annual operational time)/(Mean Failure Interval).
- JBOD = "Just a bunch of Disks", a term describing an array of independent disk volumes.
Source: Strategic Research Corporation