Disaster Recovery & Business Continuity
СТОРУС предлагает единый инструмент для виртуализации и организации резервных копий виртуальных дисков как в рамках одного массива (snapshots) так и на резервных массивах, независимо от их географического положения (synchronous/asynchronous mirroring, replication) и производителя. Этот инструмент основан на продуктах компании FalconStor (www.falconstor.com).
Виртуализация
· Теория
· Что дает виртуализация
· СТОРУС Virtualization Appliance
· Репликация
· SnapShot
· Синхронный мирроринг
· Асинхронный мирроринг
· Репликация по расписанию
Adaptec Snap Server
Полезные ссылки
Помощь
консультанта
ВИРТУАЛИЗАЦИЯ
Теория
Определение: Отображение
одного или нескольких физических блоков на поверхности жестких дисков
на логический ресурс (виртуальный пул дисков) называется виртуализацией.
Пул делится на виртуальные диски (см.
рис 1).
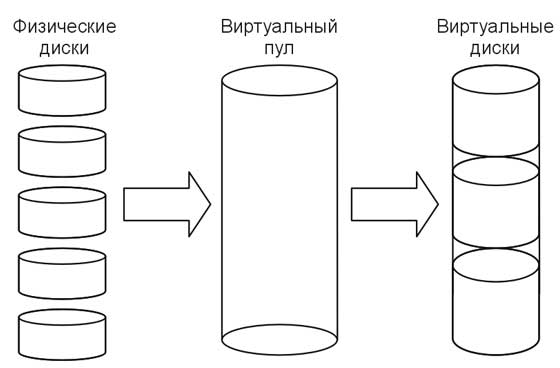
Рис.1 Процесс преобразования физических дисков в виртуальный пул, а затем разбиения виртуального пула на виртуальные диски.
Виртуальные диски закрепляются за хостами. В виртуальный пул могут объединяться, как диски внутри одного, так и нескольких массивов, создавая единое виртуальное пространство. Несколько виртуальных дисков можно создать на «территории» одного физического диска. Аналогично, один виртуальный диск может «захватить территорию» нескольких дисковых массивов, причем граница его может «пролегать» как по границам физических дисков, так и по их поверхностям.
Что дает виртуализация?
1. Единый инструмент для управления виртуальным ресурсом SAN как то:
a) разбиение на виртуальные диски
b) динамическое перераспределение виртуальных дисков между хостами
c) динамическое изменение размеров виртуального диска в соответствии с потребностями приложений
d) создание резервных копий виртуальных дисков как внутри массива, так и на других массивах, в независимости от расстояния между ними и автоматическое переключение на резервные копии при выходе из строя рабочего диска.2. Увеличение производительности в рамках одного массива. Виртуальный диск «стремится» разлиться по максимально доступному числу физических дисков, таким образом, каждый физический диск в составе виртуального содержит минимальный по размеру фрагмент физического блока. Это значительно ускоряет операцию чтения/записи.
СТОРУС Virtualization Appliance
Virtualization Appliance – это аппаратно-программный комплекс, реализованный на платформе Intel с 2мя процессорами Xeon последнего поколения и базовым программным обеспечением виртуализации от FalconStor под управлением Linux. В базовой конфигурации комплекс поставляется с 4мя портами FC (два target, два initiator) и двумя портами GbitE. Дисковые массивы могут подключаться к FC портам комплекса, либо, к портам FC коммутатора, находящимся в одной зоне с комплексом. На рис.2 приведен простейший пример виртуализации.
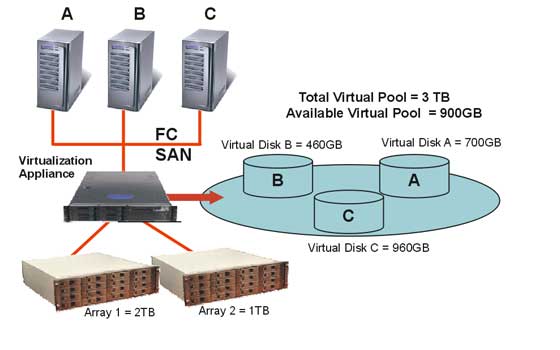
Рис. 2: Виртуализация физического пространства двух массивов RIVA 2500.
Virtualization Appliance представляет
физическое пространство массивов 1 и 2 как виртуальный пул суммарной
емкостью 3 терабайта. С помощью центральной консоли FalconStor,
администратор создает виртуальные диски A, B и C и делает их доступными
серверам A, B и C. В зависимости от потребности приложения серверов
в дисковом пространстве, диски «пульсируют», сжимаясь и отдавая
«лишнюю» емкость виртуальному пулу, или, наоборот, расширяясь и
забирая у него свободную емкость. Таким образом, достигается наиболее
оптимальное использование ресурсов.
Виртуальные диски могут иметь различные
уровни RAID.
РЕПЛИКАЦИЯ
Дополнительно к Virtualization Appliance,
можно приобрести опции репликации и агенты необходимые для создания
отказоустойчивых сред. Одним из наиболее часто используемых методов
является репликация.
Существуют два класса репликации.
Первый, репликация виртуальных дисков внутри одного массива. Второй,
репликация виртуальных дисков на резервный массив или несколько
массивов. Рассмотрим эти классы подробнее.
Snapshot
Реплику рабочего виртуального диска внутри одного массива часто называют моментальным снимком (snapshot). Для создания реплики, администратор выделяет дисковое пространство внутри самого массива и устанавливает расписание, по которому snapshot будут делаться. Различают два метода snapshot: полный и динамический. При полном методе, snapshot диски равны по объему рабочим дискам, так как на snapshot диске создается полная копия рабочего диска. Процесс происходит в фоновом режиме, и snapshot диск фактически всегда доступен. При динамическом методе на snapshot диск записываются только те блоки рабочего диска, которые будут подвержены модификации. Поэтому, дисковое пространство динамического snapshot выделяется в соответствии с размером модифицируемых блоков.
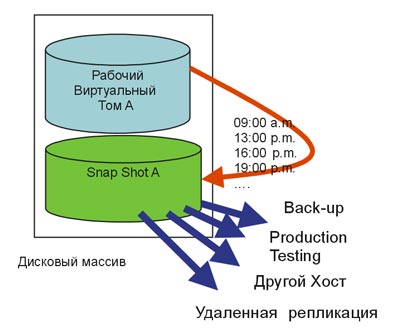
Рис 3.a: Полный snapshot
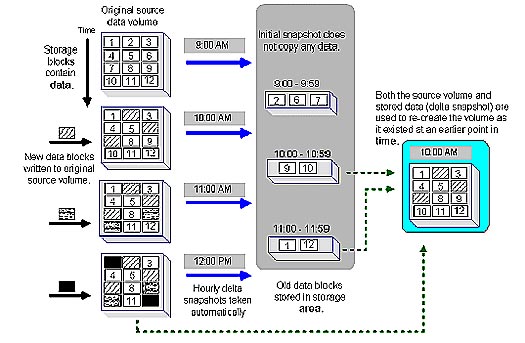
Рис. 3b: Динамический snapshot
По аналогии с back-up полный и динамический
snapshot напоминают соответственно полный и инкрементный back-up,
с той лишь разницей, что данные на сжимаются и не архивируются,
а имеют вид оригинала, что позволяет восстанавливать их несравнимо
быстрее.
У разных производителей дисковых массивов
методы организации snapshot называются по-разному. У HP "snapclonе"
и "vsnap", у IBM "business copy", "full
and incremental replication" у EMC, Shadow Image™ у Hitachi,
и т.д.
Мы, в СТОРУС, называем полный snapshot
– Snapshot Copy, а динамический snapshot – TimeMark™.
Диск-реплика, созданный при помощи
Snapshot Copy, является полной копией рабочего диска и может быть
использован в качестве резервного, отдан процессу back-up, отдан
другому хосту в целях внедрения или тестирования, отдан процессу
удаленного мирроринга или репликации.
Диск-реплика, созданный при помощи
TimeMark™, является копией лишь тех блоков данных которые в следующий
момент времени будут изменены. И позволяет "откатится" назад в любую
временную точку. Таких точек может быть до 256 на один диск. Данный
метод применяется для устранения «мягких» ошибок, таких как, восстановление
случайно удаленных или измененных данных, устранения последствий
деятельности вирусов, хакеров и т.д.
Два метода могут использоваться совместно,
по аналогии с полным и инкрементным back-up. Например, в 20:00 каждый
день создавать Snapshot Copy, а каждые 5 минут TimeMark™.
Опции Snapshot Copy и TimeMark™
устанавливаются непосредственно на комплекс Virtualization Appliance.
FalconStor поддерживает большинство
платформ, ОС и приложений.
Репликация между массивами
Существует два метода репликации между массивами: мирроринг (mirroring) и репликация по расписанию. В свою очередь мирроринг может осуществляться в синхронном или асинхронном режиме. В отличие от репликации по расписанию (или копирования по расписанию), мирроринг – это непрерывное копирование всех физических блоков одного массива на другой.
Синхронный мирроринг
Это самый надежный метод репликации.
Физический блок не запишется на главный массив до тех пор, пока
контроллер резервного массива не «сообщит» об успешной записи на
него этого блока. Поэтому, при использовании этого режима при удаленных,
даже на несколько километров, соединениях массивов, важно обеспечить,
по крайней мере, равный по скорости местному соединению канал. Например,
если в главном здании поддерживается скорость 2 Гбит/сек, то и канал
между главным и резервным центрами должен поддерживать не менее
2 Гбит/сек. Также, важно чтобы производительность резервного массива
была не хуже основного. Еще один важный фактор – расстояние. (/articles/san_long_distance_2.htm).
Известно, что скорость света в оптоволокне ниже скорости света.
С увеличением расстояния – увеличивается время прохождения света
по волокну. Здесь важно знать какую физическую среду, метод передачи
сигнала и протокол использовать при обеспечении соединения на то
или иное расстояние. Например, протокол Fibre Channel, при наличии
одномодового кабеля, хорош на расстояния до 80 км.
При больших расстояниях, рекомендуется использовать DWDM (Dense
Wave Division Multiplexing) и протокол SONET (/docs/ciena.pdf).
Для обеспечения синхронного метода,
вы можете приобрести опцию synchronous
mirroring
Репликация может производится между
массивами любых производителей.
Асинхронный метод
Асинхронный метод отличается от синхронного
тем, что блок данных сразу пишется на главное хранилище, не дожидаясь
подтверждения от удаленного. Хорош для приложений, «терпящих» небольшую
задержку. В случае выхода из строя главного хранилища, на резервном
будет копия, возраст которой будет примерно равняться задержке канала.
Этот метод обычно применяется для обеспечения репликации массивов
на большие расстояния (от 100 км.), или там, где в качестве протокола
используется IP. В этом методе, также допускается применение недорогих
резервных массивов, например с дисками sATA.
Для обеспечения асинхронного метода,
вы можете приобрести опцию asynchronous
mirroring.
Репликация по расписанию
Этот метод аналогичен
snapshot, но только на удаленный массив. Вы можете создавать как
полную копию, так и записывать только «предизмененное» состояние
как в методе TimeMark ™.
Для обеспечения синхронного метода,
вы можете приобрести опцию replication
option.
Все три вышеперечисленных метода прекрасно сочетаются с snapshot и TimeMark ™ в случае, если вы не хотите чтобы удаленная репликация осуществлялась с рабочих томов.
Adaptec Snap Enterprise Data Replicator (Snap EDR)
Еще одним выбором решения защиты территориально удаленных данных является использование высокопроизводительного Snap Enterprise Data Replicator (Snap EDR) для централизованной гетерогенной репликации широко распространенных корпоративных данных в сочетании с рентабельным хранилищем Snap Server™ от Snap Appliance™, чтобы надежно сохранить, защитить и управлять данными в сетях LAN или WAN.
Средства навигации Network Appliance® Filers обычно располагают по крайней мере одним или большим количеством серверов, сохраняющих данные установленных в сети накопителей на filer. Один или большее количество этих серверов могут использоваться как шлюз, чтобы надежно и эффективно передать территориально удаленные данные от Snap Server на NAS или наоборот. Агент Snap EDR устанавливается на сервер шлюза, и устройства Snap Server передают данные между Snap Server и томами NAS. Такое гетерогенное перемещение данных обеспечивает возможность эффективной репликации и миграции данных между системами, без необходимости дорогостоящих патентованных решений для передачи гетерогенных данных.
Устройства Snap Server и агенты Snap EDR устанавливаются в каждой удаленном месте, чтобы обеспечить рентабельное хранения данных для территориально удаленных данных, и действуют в качестве промежуточного пункта для данных, которые должны быть переданы. Работы по передаче данных затем планируются, основываясь на определенных пользователем правилах и политике, чтобы обеспечить защиту и передачу данных территориально удаленных офисов соответственно необходимости, с наименьшим воздействием на работу всех офисов.
Полезные ссылки
1) Серия статей, посвященная описанию сущности виртуализации, ее
преимуществ для бизнеса, архитектуре виртуализации, а также представлению
некоторых решений, в частности решения от Chaparral/FalconStor.
/articles/san_raidar_ps_virtualization.htm
/articles/san_raidar_ps_virtualization_2.htm
/articles/san_raidar_ps_virtualization_3.htm
/articles/san_raidar_ps_virtualization_4.htm
2) В документе приводится описание способов репликации данных для
устройств Raidtec SNAZ с использованием программного обеспечения
SNAZ™ RepliFile.
/articles/replication.htm